AI Sovereignty Is More Than Data Residency


AI Sovereignty Is Decided by More Than Where Your Data Sits
We’ve been asking an incomplete question.
Most conversations about AI sovereignty start with data. Is it stored in country. Is it in the cloud. Who has access to it.
Those questions matter. They determine whether sensitive data is exposed to foreign laws, whether privacy regulations are being met, and whether organizations can safely adopt AI at all.
But they don’t tell you whether your system is actually under control.
Because sovereignty does not live in one place. It is shaped across the entire system.
A System View of AI
To make this more concrete, I mapped how an AI system actually works end to end.
This diagram shows how data moves from source to decision to action across three common architectures. Edge, locally managed, and globally hosted.
More importantly, it highlights where different types of risk show up along the way. Not just where data sits, but where control can break.
There are two kinds of risk running through this system. Where data is exposed, and how decisions are made.

What this diagram shows is not just a comparison of edge, local, and cloud architectures. It is a map of how an AI system actually works from end to end.
Data is created at the source. It moves through networks. It is stored somewhere. Models interpret it. Decisions are made. Actions are triggered in the real world.
At every step, a different type of risk is introduced.
Some of those risks relate to where data resides. But the most critical ones emerge when data is turned into decisions.
A Real World Scenario
A patient is being monitored at home for early signs of cardiac deterioration. Their wearable continuously captures heart rate, oxygen levels, and activity. The goal is to detect subtle changes early enough to intervene before a crisis.
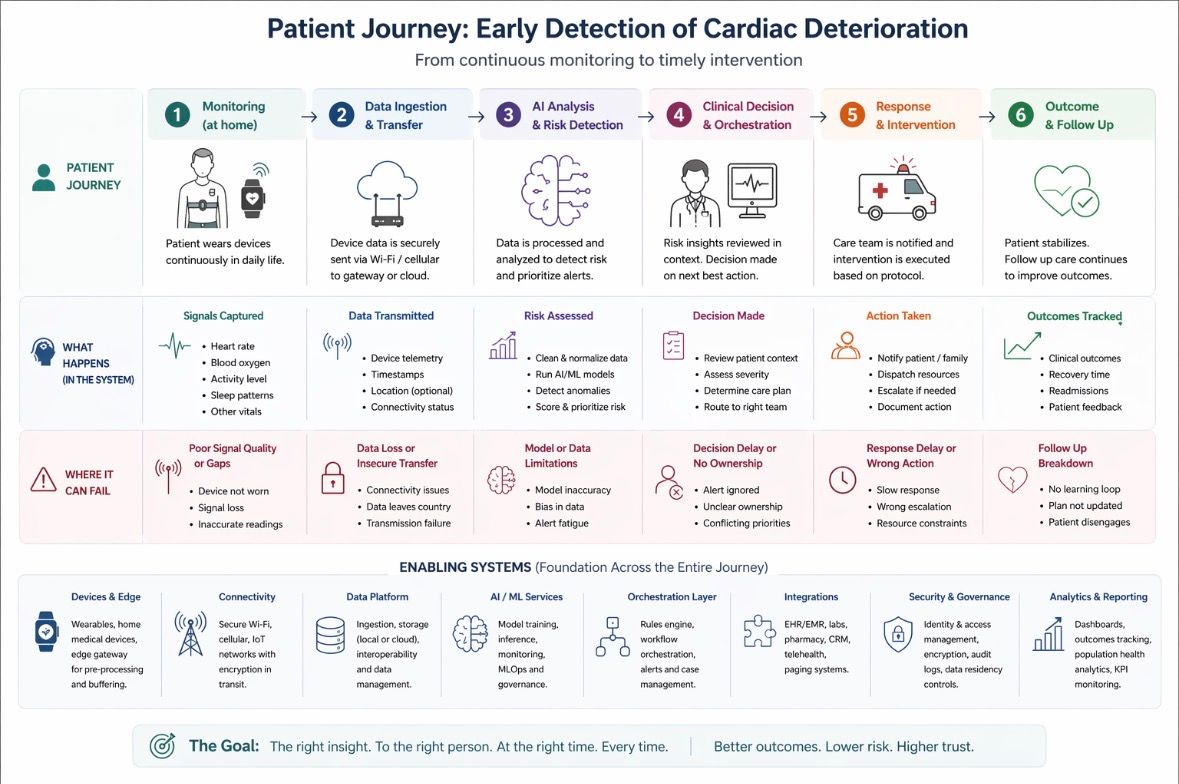
Now ask a simple question. Where could this system fail.
1. When Data Leaves the Country
When patient data is transmitted or stored outside the country, it becomes subject to the laws of that jurisdiction. This creates jurisdictional access risk. In practical terms, this means a foreign government may have the legal right to request access to that data under its own laws. That access can happen without the patient’s knowledge, and the healthcare provider who collected the data may have limited ability to prevent it.
This also creates compliance exposure. Healthcare organizations are required to follow strict privacy laws that define where data can be stored and how it must be protected. If data is moved across borders, those requirements may no longer be met. That can lead to legal liability, regulatory penalties, and a loss of trust from patients.
These are not abstract concerns. They directly affect whether organizations can confidently deploy AI systems in the first place.
2. When the Model Gets It Wrong
Even if data is perfectly protected and compliant, the system can still fail. If the AI model misinterprets the patient’s data, it may fail to detect early signs of deterioration. It may signal that everything is fine when intervention is actually needed.
The impact here is clinical. A missed signal can delay care, increase risk, and lead to outcomes that could have been prevented.
This is not about where the data sits. It is about whether the intelligence built on that data is reliable.
3. When No One Owns the Decision
Even with accurate data and a strong model, someone still needs to decide when to act, who is responsible for responding, and what action should be taken.
If that decision layer is fragmented across systems, teams, or vendors, the system does not fail loudly. It fails quietly.
Signals are generated but not acted on. Alerts exist but are not owned. Decisions are delayed because responsibility is unclear.
In a real scenario, this can mean a patient shows early signs of deterioration, the system detects it, but no one intervenes in time.
The system appears to be working. But the outcome still fails.
This is where most real world risk sits.
What Architecture Choices Actually Do
When you step back, edge, locally managed, and globally hosted systems are not better or worse. They are trade offs.
Edge computing keeps data close to the source and reduces exposure, but limits how sophisticated and adaptable the model can be.
Locally managed systems provide stronger control over data and infrastructure, but can introduce bottlenecks in decision making and execution.
Globally hosted systems enable powerful models and rapid innovation, but increase dependency on external providers and reduce visibility into how decisions are made.
None of these approaches on their own guarantees sovereignty.
What AI Sovereignty Actually Means
Because sovereignty is not a location. It is a system property.
AI sovereignty exists when an organization can determine where its data resides and who can access it, control how that data flows through its systems, govern how decisions are made from that data, and remain accountable for the outcomes those decisions produce.
If any one of these breaks, sovereignty starts to erode.
The Shift That Matters
So the shift is simple, but not easy.
Instead of asking where is our data stored, we should be asking where do we lose control across our system.
Because that is where real risk lives.
And that is exactly what this diagram makes visible.
Final Thought
AI sovereignty is often framed as a question of control over data.
But in practice, control over data does not guarantee control over outcomes.
A system can be fully compliant, locally hosted, and technically sound, and still fail the person it is meant to serve.
Because the failure does not happen at the point where data is stored.
It happens at the point where data is interpreted, decisions are made, and actions are either taken or missed.
That is where real risk lives.
And that is where sovereignty is either designed into the system or quietly lost.
What This Raises
If that is true, it raises a different set of questions.
Who should control decisions in an AI driven system.
Who owns the orchestration layer that turns signals into action.
And how do you create clarity across that complexity so outcomes are consistently delivered and owned.
One way to approach this is by anchoring on outcomes and working backwards through the system.
What does that actually look like in practice.
I will walk through a real world example of how an outcomes based approach can be applied here.
Stay tuned for more on this next week.